Understanding Apache Kafka and How it Can Make Your Business More Efficient: Part 1

In this four-part series, we will talk about the Apache Kafka platform, understand basic terminology and concepts, learn about how Apache Kafka can help take your business to the next level in efficiency and scalability, and finally look at some real-world case studies.
This will be a simple guide for non-techies and developers who wish to get more familiar with the platform and its benefits.
Welcome to Part 1. You probably arrived here because you heard something about Apache Kafka and wanted to learn more about the platform and how it might fit into your business IT infrastructure.
In a nutshell, Kafka is a publish-subscribe messaging system that enables you to build distributed applications.
For one client, we are using Kafka to solve user management issues by synchronizing data across multiple systems and user applications. For another, we are using Kafka to integrate data between project management, accounting and scheduling applications.
If you need to automate sending or receiving information between virtually any type of source & destination, this can likely be achieved with Kafka.
Apache Kafka History
Kafka was first developed in 2008 by a development team at LinkedIn, the online social networking website for businesses and professionals. The original authors were Jay Kreps, Neha Narkhede and Jun Rao.
The platform was open-sourced in 2011 and adoption took off rapidly as shown in the graph below from Stack Overflow community help forums.

And to this day the platform continues to gain market share:.

More than one-third of all Fortune 500 companies use Kafka. Currently there are almost 100,000 companies reportedly using Kafka in their tech stacks, including Uber, Airbnb, Spotify, and Netflix, to name a few.

Companies from a wide range of industries are using Kafka to process huge volumes of data that need to be processed as they occur and analyzed in real-time.
Data is the lifeblood of the modern enterprise. Kafka helps these companies monitor, process and discover trends, apply insights, and react to customer needs with a cost-effective, resilient and scalable real-time data processing solution.
What Are the Business Benefits of Using Apache Kafka?
In a nutshell, Kafka moves large amounts of data in a reliable way and is a flexible tool for communicating that data to a wide range of applications.
Data can be transformed into actionable insights used by business managers to make informed decisions. It enables those decision makers to process data quickly and determine what is working and what is not.
Now the typical source of data — transactional data such as orders, inventory, and shopping carts — is enriched with other data sources: recommendations, social media interactions, search queries.
All of these data sets can feed analytics engines and help companies win customers and increase sales.
Kafka is easy to set up and use. It has excellent performance, is stable, provides reliable durability, and has robust replication.
Scalability is also a major selling point when thinking of adding Kafka to your IT stack. The Kafka system is distributed over different data centers and is easy to expand and operate as a service.
This allows applications to be agile from a development and dev-ops point of view.
While Kafka is mostly used for real-time data analytics and stream processing, it can also be used for log aggregation, messaging, click-stream tracking, audit trails, and much more.
So What is Apache Kafka?
Apache Kafka is a distributed streaming platform for building real-time data pipelines and real-time streaming applications. The platform is capable of handling trillions of events a day.
The platform was conceived as a way to handle continuous streams of data with low latency and high-performance.
For example think of all the data that is being produced in a seemingly simple Uber driver/passenger interaction.
Just some of the datasets might be: location, availability, scheduling, traffic, tariffs, routing, user reviews, driver reviews, etc. All of this data is coming in at real-time and would be impossible to store and process in a conventional database configuration.
Jay Kreps, one of the original authors of Apache Kafka said,
Our idea was that instead of focusing on holding piles of data like our relational databases, key-value stores, search indexes, or caches, we would focus on treating data as a continually evolving and ever growing stream, and build a data system — and indeed a data architecture — oriented around that idea.
Kafka is generally used for two broad classes of applications:
Building real-time streaming data pipelines that reliably get data between systems or applications
Building real-time streaming applications that transform or react to the streams of data
Understanding How Apache Kafka Works
To understand how Kafka works, we first need to go over some of the terminology used by Apache Kafka.
At its core are three main concepts:
Producer: An application that produces or writes to a data stream
Consumer: An application that subscribes or reads a data stream
Topic: A log of events that occur in a particular data stream
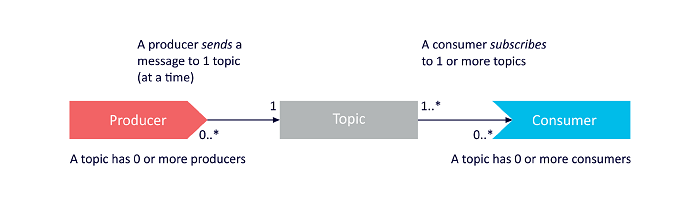
Kafka sits between producers of data and consumers of data. The producing application sends a message to a Kafka topic, and the recipient or consumer application receives messages from that Kafka topic.
Kafka allows messages to flow between different applications with high-throughput and low-latency in a real-time data feed.
Now that you have the basic understanding of how data moves in the Kafka platform, we will now look closer at Topics and how they are built.
Topics are where records are published. The data is published sequentially with an identifying number (called the offset) which could also be understood as a structured commit log.

Producers write and publish data to a Topic.
Consumers subscribe and read data from several Topics.
Topics are stored and replicated across servers for redundancy and that data can be stored as long or as short as is necessary.

Several Topics can be grouped together in a Broker.
Brokers are grouped together in what is known as a Cluster.
The diagram below gives a visual understanding of the typical Kafka architecture.

A Cluster lives on one or more servers and can span across multiple datacenters.
• The Kafka cluster stores streams of records in categories called topics.
• Each record consists of a key, a value, and a timestamp.
The Zookeeper at the bottom of the diagram will be explained in the next article as we dive deeper how Kafka works.
Now we move into the final part in our understanding of the different terms and concepts of Apache Kafka. Kafka APIs.
Kafka has four major APIs:
The Producer API allows an application to publish a stream of records to one or more Kafka topics.
The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.

In our next article we will go over how Apache Kafka is used in a real-world scenario and how these different parts of Kafka work together to create a dynamic and powerful system to read, write and analyze data as it happens in real-time.